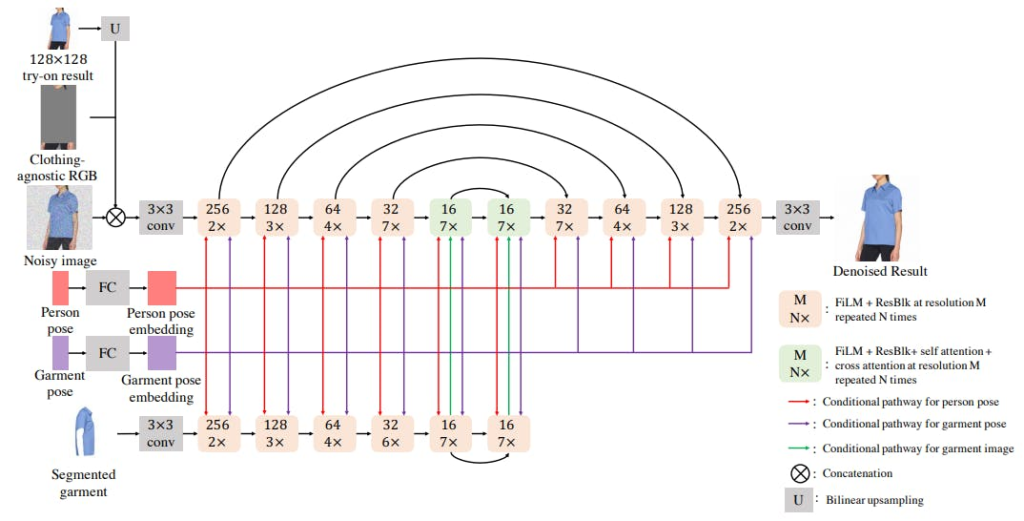
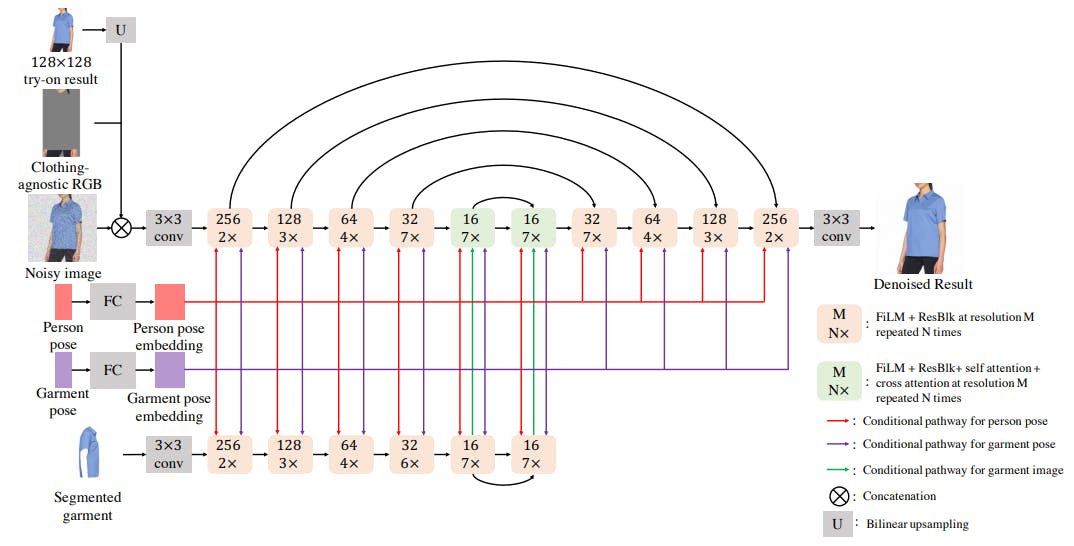
Authors:
(1) Luyang Zhu, University of Washington and Google Research, and work done while the author was an intern at Google;
(2) Dawei Yang, Google Research;
(3) Tyler Zhu, Google Research;
(4) Fitsum Reda, Google Research;
(5) William Chan, Google Research;
(6) Chitwan Saharia, Google Research;
(7) Mohammad Norouzi, Google Research;
(8) Ira Kemelmacher-Shlizerman, University of Washington and Google Research.
TryOnDiffusion was implemented in JAX [4]. All three diffusion models are trained on 32 TPU-v4 chips for 500K iterations (around 3 days for each diffusion model). After trained, we run the inference of the whole pipeline on 4 TPU-v4 chips with batch size 4, which takes around 18 seconds for one batch.