The Role of Human-in-the-Loop Preferences in Reward Function Learning for Humanoid Tasks | HackerNoon
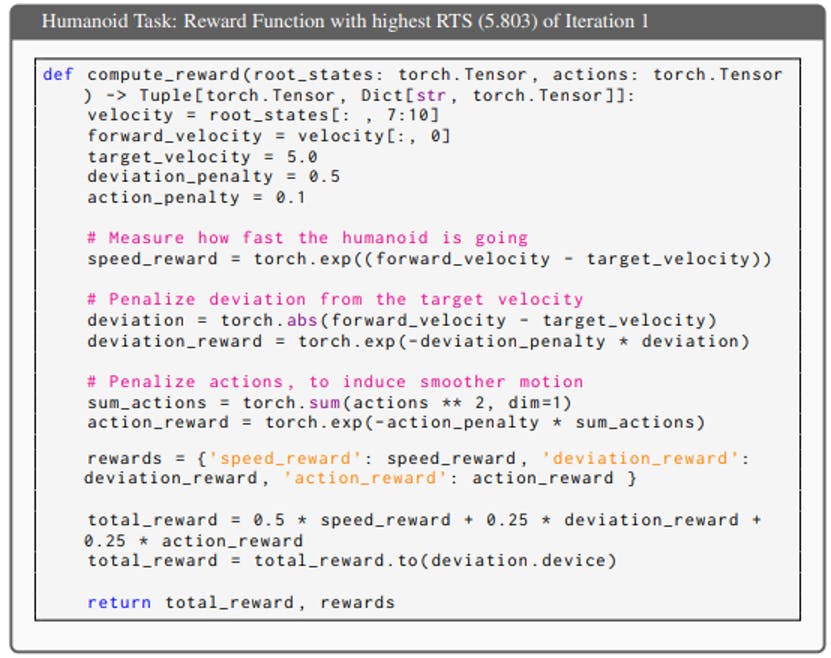
Table of Links Abstract and Introduction Related Work Problem Definition Method Experiments Conclusion and References A. Appendix A.1. Full Prompts and A.2 ICPL Details A. 3 Baseline Details A.4 Environment Details A.5 Proxy Human Preference A.6 Human-in-the-Loop Preference A.6 HUMAN-IN-THE-LOOP PREFERENCE A.6.1 ISAACGYM TASKS We evaluate human-in-the-loop preference experiments on tasks in IsaacGym, including Quadcopter, Humanoid, Ant, ShadowHand, and AllegroHand. In these experiments, volunteers only provided feedback by comparing videos showcasing the final policies derived