As the semiconductor industry continues to evolve, Arm stands at the forefront of innovation for its core and IP architecture, especially in the mobile space, by pushing the boundaries of technology to deliver cutting-edge solutions for end users. For 2024, Arm’s year-on-year strategic advancements focus on enhancing last year’s Armv9.2 architecture with a new twist. Arm has rebranded and re-strategized its efforts by introducing Arm Compute Subsystem (CSS), the direct successor to last year’s Total Compute Solutions (TSC2023) platform.
Arm is also transitioning its latest IP and Cortex core designs, including the largest Cortex X925, the middle Cortex A725, and the refreshed and smaller Cortex A520 to the more advanced 3 nm process technology. Arm promises that the 3 nm process node will deliver unprecedented performance gains compared to last year’s designs, power efficiency and scalability improvements, and new front and back-end refinements to its Cortex series of cores. Arms’ new solutions look to power the next-generation mobile and AI applications as Arm, along with its complete AArch64 64-bit instruction execution and approach to solutions geared towards mobile and notebooks, look set to redefine end users’ expectations within the Android and Windows on Arm products.
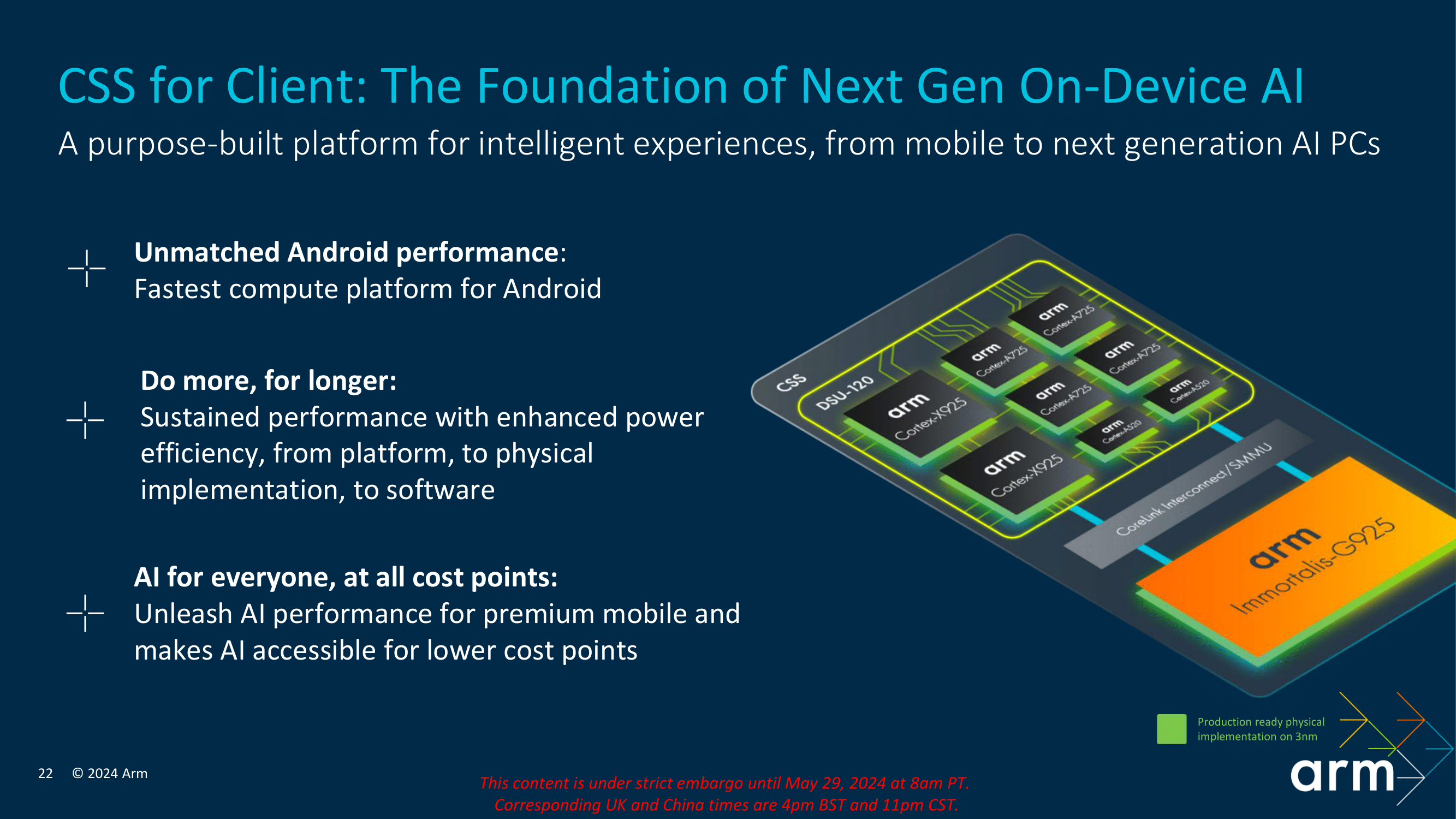
The introduction of Arm Compute Subsystem (CSS) marks a significant milestone in Arm’s strategy to deliver a holistic and full-rounded computing solution for partners to implement in their new yearly cycle of mobile devices. CSS is a comprehensive platform that integrates hardware, software, and tools to optimize the performance and efficiency of client devices. It is designed to provide a seamless computing experience across various devices, from smartphones and tablets to laptops and even desktop PCs.
When launched last year, the Armv9.2 architecture represented a significant step forward in Arm’s roadmap. Still, this year, it’s about building on the successes of its predecessors while introducing a host of new features and improvements. One of the key highlights of the revamped Armv9.2 family is the use of enhanced security features, which include memory tagging extensions (MTE) and confidential compute architecture (CCA). These features provide robust protection against various security threats, making devices more secure.
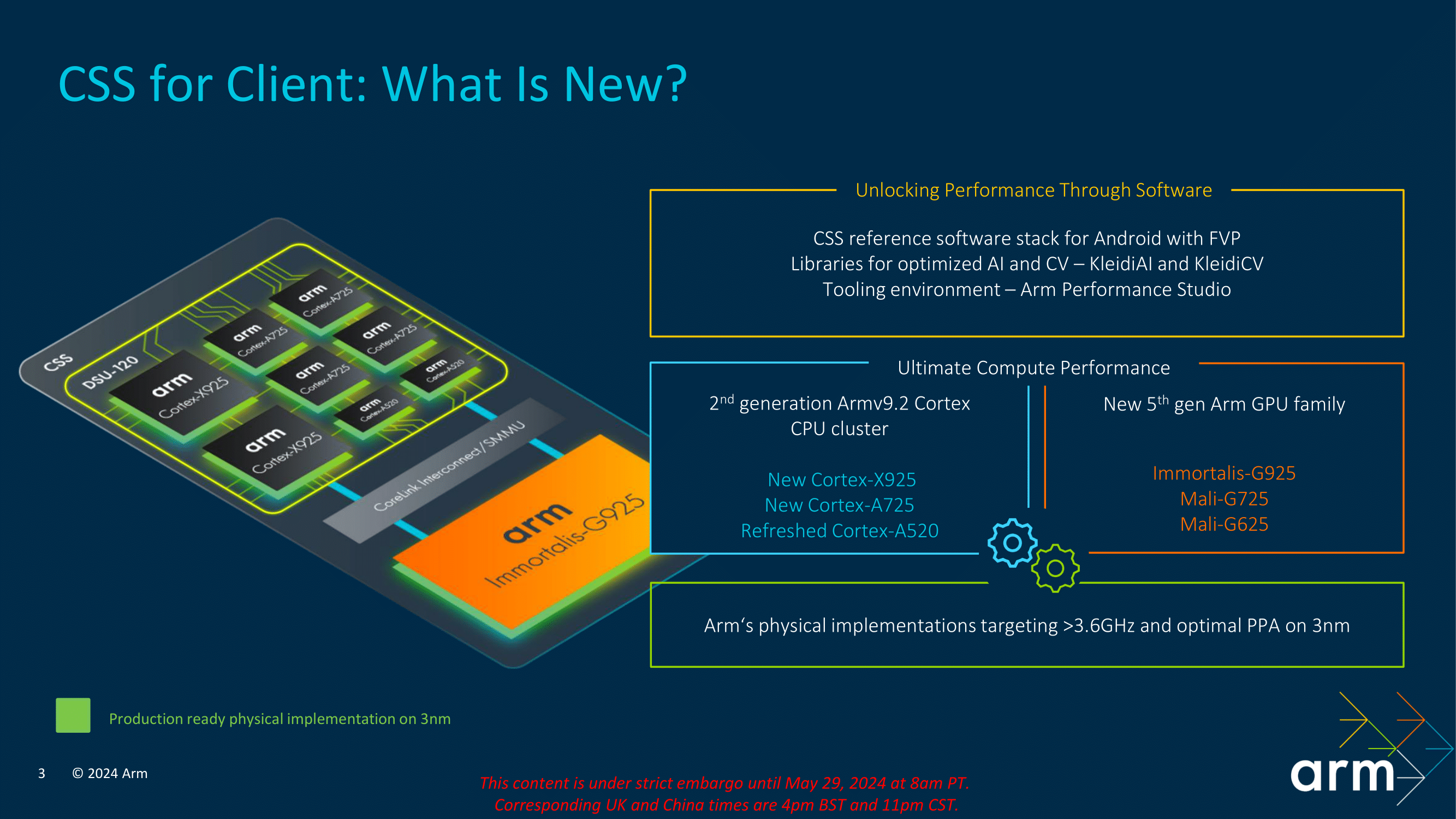
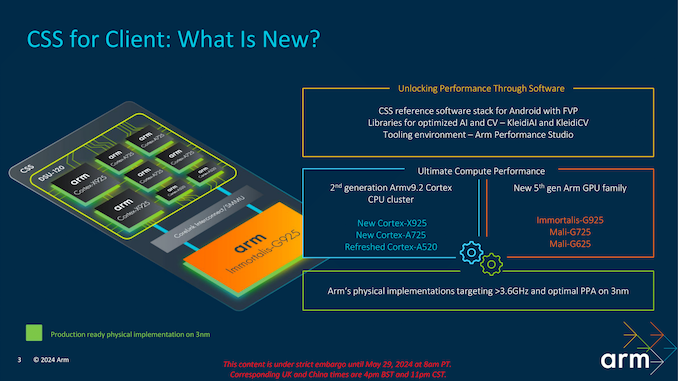
CSS leverages the latest Armv9.2 cores designed for 2024, including the high-performance Cortex X925, the balanced Cortex A725, and the power-efficient and refreshed Cortex A520. These cores are complemented by Arm’s new Immortalis G925 GPU, designed to deliver exceptional graphics performance and efficiency in a mobile-sized package. Together, these components form the foundation of what is now called the CSS platform, which aims to provide a powerful and versatile computing solution for modern devices in the mobile sphere.
One of CSS’s key features is its robust scalability for different markets, such as mobile and notebooks. The platform is designed to scale across different device form factors and performance requirements, making it suitable for many tasks and applications. Whether it’s high-end gaming, professional content creation, or everyday productivity tasks, CSS can be tailored to meet the needs of various use cases.
Arm’s Arm Compute Subsystem (CSS) platform represents a significant step forward in IP design and architectural improvements, offering multiple and claiming serious levels of enhancements in performance and efficiency. With the introduction of the second-generation Armv9.2 Cortex CPU cluster, including the new Cortex-X925 (big), Cortex-A725 (middle), and a refreshed Cortex-A520 (little) cores, the CSS platform is designed to deliver the ultimate in mobile computing performance when licensed out to their partners.

Additionally, the CSS platform includes a comprehensive reference software stack for Android, optimized AI backed by new Arm computer vision libraries (KleidiAI and KleidiCV), and robust tooling environments through Arm Performance Studio. This typically holistic approach ensures that Arm’s physical implementations achieve speeds greater than 3.6 GHz and offer optimal power, performance, and area (PPA) metrics on the 3 nm node. Speaking of the 3 nm mode, Arm stated that TSMC and Samsung 3 nm are the key options for their CSS core cluster, although it’s most likely to be a case of getting fab allocations with TSMC as we are unsure if any will use Samsung over TSMC.
In addition to security enhancements, Armv9.2 on 3 nm also promises substantial performance improvements, especially with the new big core, the Cortex X925, which Arm believes is the new IPC king of the mobile. The architecture has been optimized for higher clock speeds and better levels of efficiency, which in turn should deliver more compute power per watt. This is achieved through several architectural innovations, including wider execution pipelines, improved branch prediction, and enhanced out-of-order execution capabilities. These enhancements boost the cores’ Instructions Per Cycle (IPC), ensuring they can easily handle the most demanding workloads.
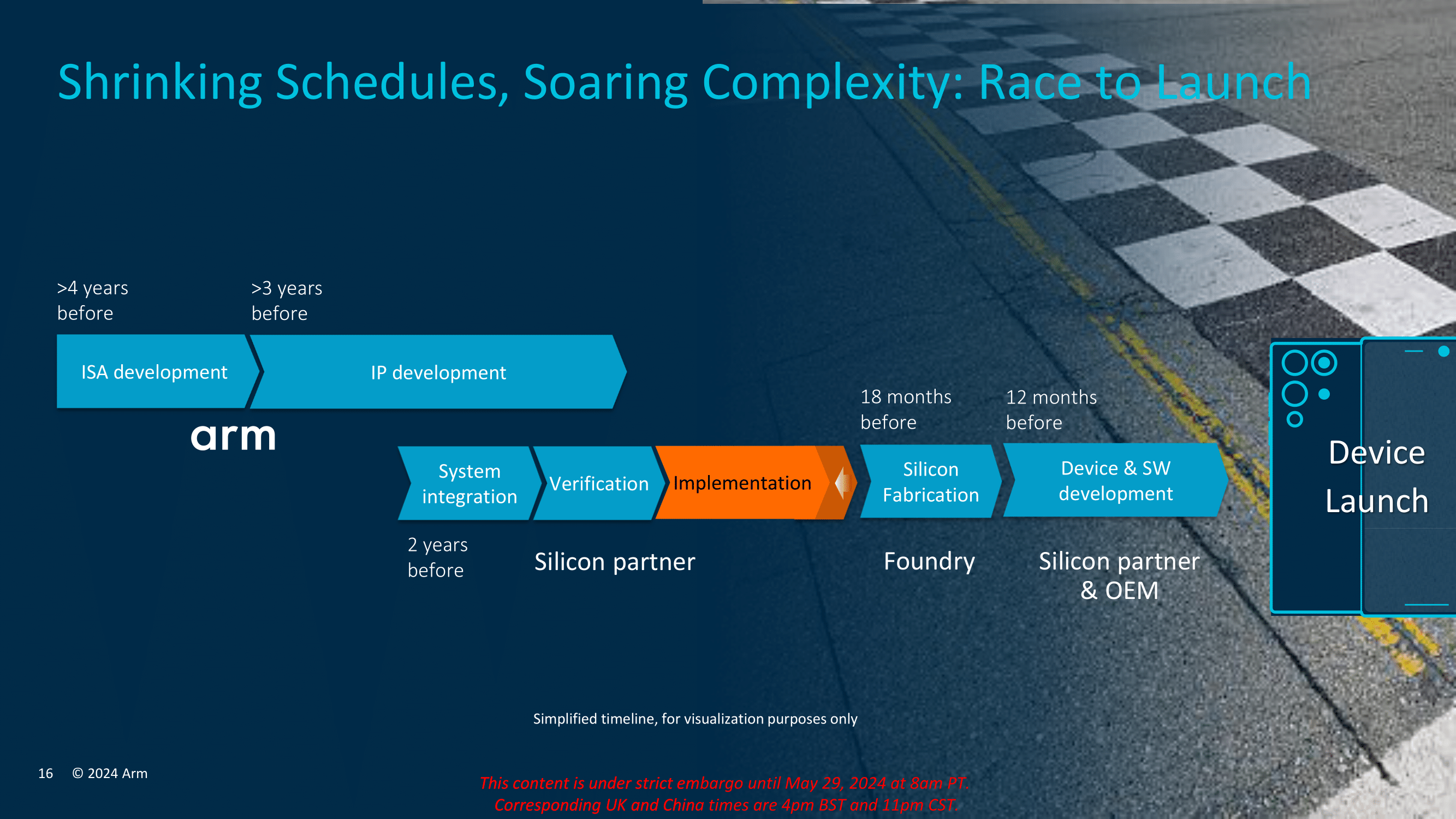
Transitioning to 3 nm Process Technology
The move to 3 nm process technology represents a significant leap in semiconductor manufacturing, offering substantial improvements in performance, power consumption, and chip density. This transition allows Arm to deliver more powerful and efficient processors capable of handling the most demanding applications efficiently.
One of the primary benefits of the 3 nm process is its ability to pack more transistors into a smaller area, resulting in higher performance and lower power consumption. This is crucial for mobile and portable devices, where battery life and thermal management are critical considerations. The 3 nm process also enables Arm to push out higher clock speeds on the Cortex X925 core, up to 3.8 GHz, to be exact. This enables faster and more responsive computing experiences and pushes overall IPC performance above and beyond what was already achievable.

The combination of the updated Armv9.2 architecture, the new CSS platform, and the jump to the 3 nm process technology, as Arm claims, is designed to roll out significant performance and efficiency enhancements across the board. This should theoretically enable various implementations of their reference CPU Core Cluster designs for devices of all ilks, with two Cortex X cores being the go-to norm now, as opposed to just one from last year’s reference design. Benchmarks and real-world tests conducted and presented by Arm, which should be taken with a grain of salt, show substantial gains in single-threaded and multi-threaded performance, making these new solutions ideal for various applications. Arm is even claiming single-threaded IPC leadership with the largest core, the Cortex X925, surpassing what both Intel and AMD are capable of, which is a bold claim.
Regarding power efficiency, the new cores are designed to deliver more compute power per watt, reducing energy consumption and extending battery life. This is particularly important for mobile devices, where users demand long battery life without compromising performance. The improved power efficiency also translates to better thermal management, ensuring that devices remain cool and responsive even under heavy workloads.
In addition to performance and efficiency improvements, the new solutions also bring enhanced security and AI capabilities. The Armv9.2 architecture’s memory tagging extensions (MTE) and confidential compute architecture (CCA) provide robust protection against various security threats, ensuring that data and applications remain secure.
The enhanced AI capabilities of the new cores and GPUs are also noteworthy. With AI’s increasing importance in modern applications, the new solutions are designed to accelerate AI workloads, delivering faster and more efficient AI processing. This is achieved through dedicated AI accelerators and optimizations that leverage the full potential of the new architecture and process technology.
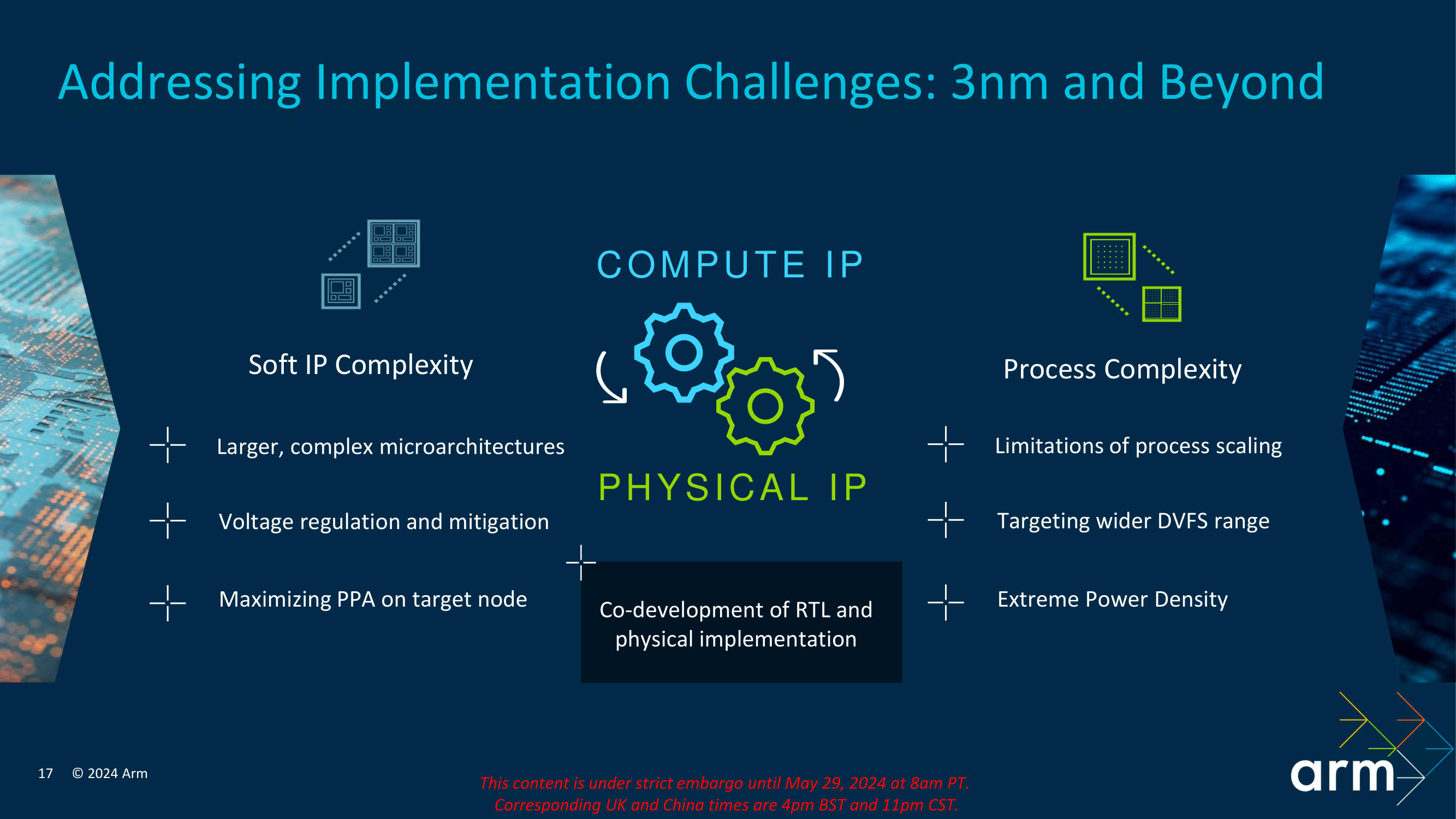
Process technology migration to 3 nm presents many opportunities and challenges for semiconductor manufacturing. For soft IP, bigger and more complex microarchitectures need stronger voltage regulation and mitigation to ensure stability and performance. The key objective is to optimize the right PPA (Power, performance, area) on the target node. For physical IP, process complexity brings its own challenges, including scaling limitations and the requirement to support a wider dynamic voltage and frequency scaling (DVFS) spectrum. Furthermore, with extreme power density, this should mitigate thermal issues, and ensuring things are running efficiently, which is very important in a mobile device
To address these challenges, Arm takes a holistic view of RTL and physical implementation co-development. This ensures that their compute IP can meet performance expectations while overcoming the challenges of advanced process technologies.
Advancements in Armv9.2, CSS, and 3 nm technology open up new possibilities for various applications, including developers accessing the new Arm Kleidi libraries. In the mobile space, these solutions enable more powerful and efficient smartphones and tablets to handle complex tasks such as AI-powered photography, gaming, and productivity.
The new solutions deliver desktop-class performance in portable form factors for the PC market, making them ideal for laptops and 2-in-1 devices. The improved performance and efficiency also benefit professional content creation, allowing for faster rendering, editing, and multitasking.

In the AI and machine learning space, the new solutions provide the compute power needed for advanced AI applications, from natural language processing and computer vision to autonomous systems and robotics. The enhanced AI capabilities ensure these applications run efficiently and effectively, delivering faster and more accurate results.
As Arm continues to push the boundaries of semiconductor technology, the focus on enhancing the Armv9.2 architecture, introducing the CSS platform, and transitioning to the 3 nm process technology marks a significant step forward. These advancements substantially improve performance, power efficiency, and security, enabling a new generation of devices that can easily handle the most demanding applications.
Combining these technologies provides a powerful and versatile computing solution that can scale across different device form factors and use cases. Whether it’s high-end gaming, professional content creation, or everyday productivity tasks, Arm’s latest solutions are designed to deliver the best possible computing experience.
Good Hardware Benefits From Good Software
Arm’s hardware advancements are bolstered by a sophisticated software ecosystem designed to exploit the full potential of its processors. At the heart of this ecosystem are the new Kleidi libraries, which play a crucial role in optimizing artificial intelligence (AI) and computer-based applications. These libraries provide developers with tools tailored to maximize the performance and efficiency of Arm’s latest cores.

KleidiAI is a key component that focuses on accelerating AI workloads. It includes a comprehensive set of computational kernels optimized for Arm’s architecture, enabling efficient execution of various AI tasks such as machine learning, natural language processing, and data analytics. By offering highly optimized routines for common AI operations, KleidiAI allows developers to achieve significant performance gains while maintaining energy efficiency. This is increasingly important as AI applications become more prevalent in mobile devices, smart home systems, and industrial automation.
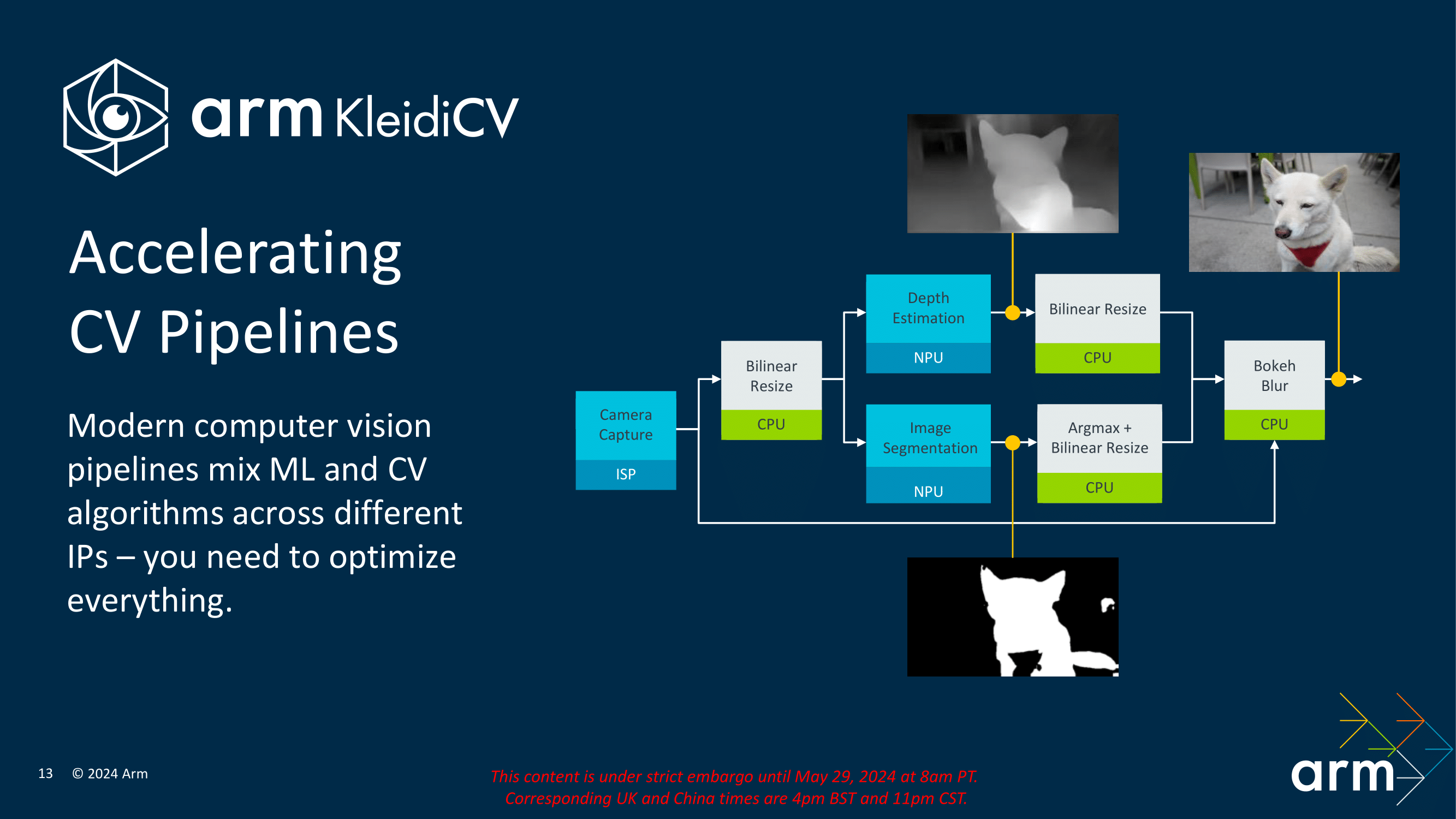
KleidiCV, on the other hand, targets computer vision workloads. This library offers optimized functions for tasks such as image processing, object detection, and scene recognition. Integrating KleidiCV with Arm’s architecture ensures that applications can handle visual data quickly and efficiently, making it ideal for use in augmented reality, autonomous vehicles, and intelligent surveillance systems. By leveraging these optimized libraries, developers can build sophisticated applications that run smoothly on Arm-based hardware, fully utilizing the performance and power efficiency improvements provided by the 3 nm process technology.
In addition to the Kleidi libraries, Arm provides a robust set of development tools and platforms. The Arm Compute Subsystem (CSS) platform includes reference software stacks and performance optimization tools like Arm Performance Studio, which offers detailed insights into application performance and helps developers fine-tune their software for maximum efficiency. This comprehensive support system ensures that developers can quickly and effectively bring innovative applications to market, taking full advantage of Arm’s latest architectural advancements.
Over the next few pages, we’ll break down Arm’s improvements within its 2024 CPU cluster, including the new Cortex X925 and Cortex A725 cores and refinements made with the smallest core, the Cortex A520.
The Arm Cortex-X925, codenamed “Black Hawk,” as Arm boldly claims, stands at the forefront of single-threaded instruction per clock (IPC) performance, setting things up for improved performance and efficiency in a big way, at least from Arm’s claims. This core is a pivotal part of Arm’s move to the 3 nm process node and integrates seamlessly into the second-generation Armv9.2 architecture. If Arms claims were taken as gospel, the Cortex X925 would be positioned as a leader in high-performance mobile computing and is an example of where Arm and its focus on a highly efficient PPA is the driving force with Arm’s 2024 CPU Core Cluster.

The Cortex-X925 is built on architectural improvements designed to maximize IPC. One of the standout features is its 10-wide decode and dispatch width, significantly increasing the number of instructions processed per cycle. This enhancement allows the core to execute more instructions simultaneously, leading to better utilization of execution units and higher overall throughput.
Arm has doubled the instruction window size to support this wide instruction path, allowing more instructions to be held in flight at any given time. This reduces stalls and improves the efficiency of the execution pipeline. Additionally, the core boasts a 2X increase in L1 instruction cache (I$) bandwidth and a similar increase in L1 instruction translation lookaside buffer (TLB) size. These enhancements ensure that the core can quickly fetch and decode instructions, minimizing delays and maximizing performance.

The Cortex-X925 also features a highly advanced branch prediction unit, which reduces the number of mispredicted branches. By incorporating techniques such as folded-out unconditional direct branches, Arm has removed several architectural roadblocks, enabling a more streamlined and efficient execution path. This leads to fewer pipeline flushes and higher sustained IPC.

The front end of the Arm Cortex-X925 showcases plenty of improvements within the design, including boosting instruction throughput and reducing latency. Central to these improvements is the 10-wide decode and dispatch width, which allows the core to handle more instructions per cycle compared to previous architectures. This wide instruction path increases the parallelism in instruction processing, enabling the core to execute more tasks simultaneously.
Additionally, the Cortex-X925 features a doubled instruction window size, accommodating more instructions in flight and minimizing pipeline stalls. The L1 instruction cache (I$) bandwidth has also been increased by 2x, along with a similar expansion in the L1 instruction translation lookaside buffer (iTLB) size. These enhancements ensure that the core can quickly fetch and decode instructions, significantly reducing fetch bottlenecks and improving overall performance.

The backend of the Cortex-X925 has seen significant growth in out-of-order (OoO) execution capabilities, with a 25-40% increase. This growth allows the core to execute instructions more flexibly and efficiently, reducing idle times and improving overall performance. Furthermore, the core’s register file structure has been enhanced, increasing the reorder buffer size and instruction issue queues, contributing to ultimately smoother and, thus, faster instruction execution.

Despite its high performance, the Cortex-X925 is designed to be power efficient. The 3 nm process technology is crucial, enabling better power efficiency than previous generations. The core’s design includes features such as dynamic voltage and frequency scaling (DVFS), which allows it to adjust power and performance levels based on the workload. This ensures energy is used efficiently, extending battery life and reducing thermal output.
The Cortex-X925 also incorporates advanced power management features, such as per-core DVFS and improved voltage regulation. These features help manage power consumption more effectively, ensuring the core delivers high performance without compromising energy efficiency. This balance is particularly beneficial for mobile devices requiring sustained performance and long battery life.

The Cortex-X925 is also designed for and optimized for AI-based workloads, with dedicated AI accelerators and software optimizations that enhance AI processing efficiency. With up to 80 TOPS (trillion operations per second), the core can handle complex AI tasks, from natural language processing to computer vision. These capabilities are further supported by Arm’s Kleidi AI and Kleidi CV libraries, which provide developers with the tools needed to build advanced AI applications.
Interestingly, Arm hasn’t moved into the realm of NPU or AI accelerators itself. Instead, it allows its partners, such as MediaTek, to incorporate their own, ensuring that the Core Cluster can provide the necessary support and integration capabilities. With its reference software stack and optimized libraries, the CSS platform provides a robust foundation for developers. The inclusive Arm Performance Studio offers advanced tooling environments that help developers optimize their applications for the new architecture.
The CSS platform’s integration with operating systems such as Android, Linux variants, and Windows through its reinvigorated Windows on Arm OS ensures broad compatibility and ease of development. This cross-operating system support enables developers to quickly and efficiently build applications that leverage the capabilities of the Cortex-X925, along with the entirety of the updated Armv9.2 Core Cluster, which not only accelerates time-to-market but ensures compatibility across multiple devices.
The Arm Cortex-A725 is designed to balance performance and power efficiency, making it a critical component of the second-generation Armv9.2 architecture. Positioned as a mid-tier core, it complements the high-performance Cortex-X925 by offering robust capabilities for everyday computing tasks while maintaining energy efficiency. This core is especially targeted at devices that require consistent performance without the high power consumption associated with top-tier cores, such as smartphones, tablets, and laptops.

The Cortex-A725 builds on the successes of its predecessor, the Cortex-A720, with several key architectural enhancements. One of the significant improvements is the increased instruction issue queue and the expanded reorder buffer, which enable the core to handle more instructions simultaneously and execute them out of order for improved efficiency. This increase in the out-of-order execution window size allows the Cortex-A725 to utilize its execution units better, leading to smoother and faster processing of complex workloads.
The core also benefits from a new 1MB L2 cache configuration, which provides faster access to frequently used data and instructions. This larger cache size is designed to reduce latency and improve performance, particularly for applications that require rapid data retrieval. Additionally, the Cortex-A725 features enhancements in its register file structure, further streamlining data processing and reducing bottlenecks.
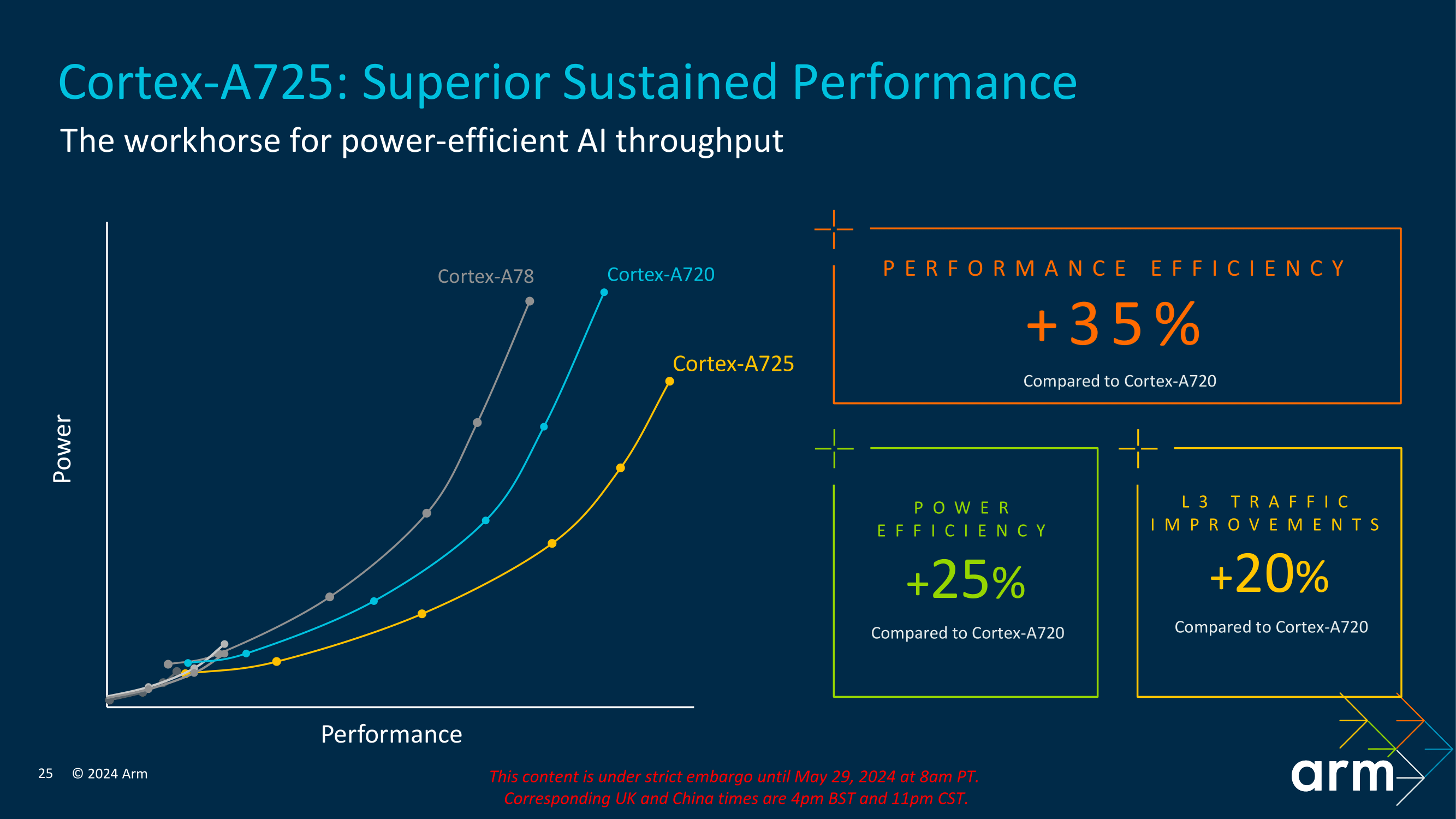
Power efficiency is a crucial aspect of the Cortex-A725’s design. With leading-edge 2024 Cortex chips expected to be fabbed on newly-available 3nm process technologies from TSMC and others, the improved performance from these nodes is able to drive big improvements in energy efficiency, and Arm is leaning into that heavily with the A725. Overall, Arm is touting that A725 delivers significant power savings compared to previous generations. Compared to the Cortex-A720, the Cortex-A725 offers up to a 25% improvement in power efficiency (and 20% L3 traffic reduction), making it an ideal choice for mobile devices that require long battery life.
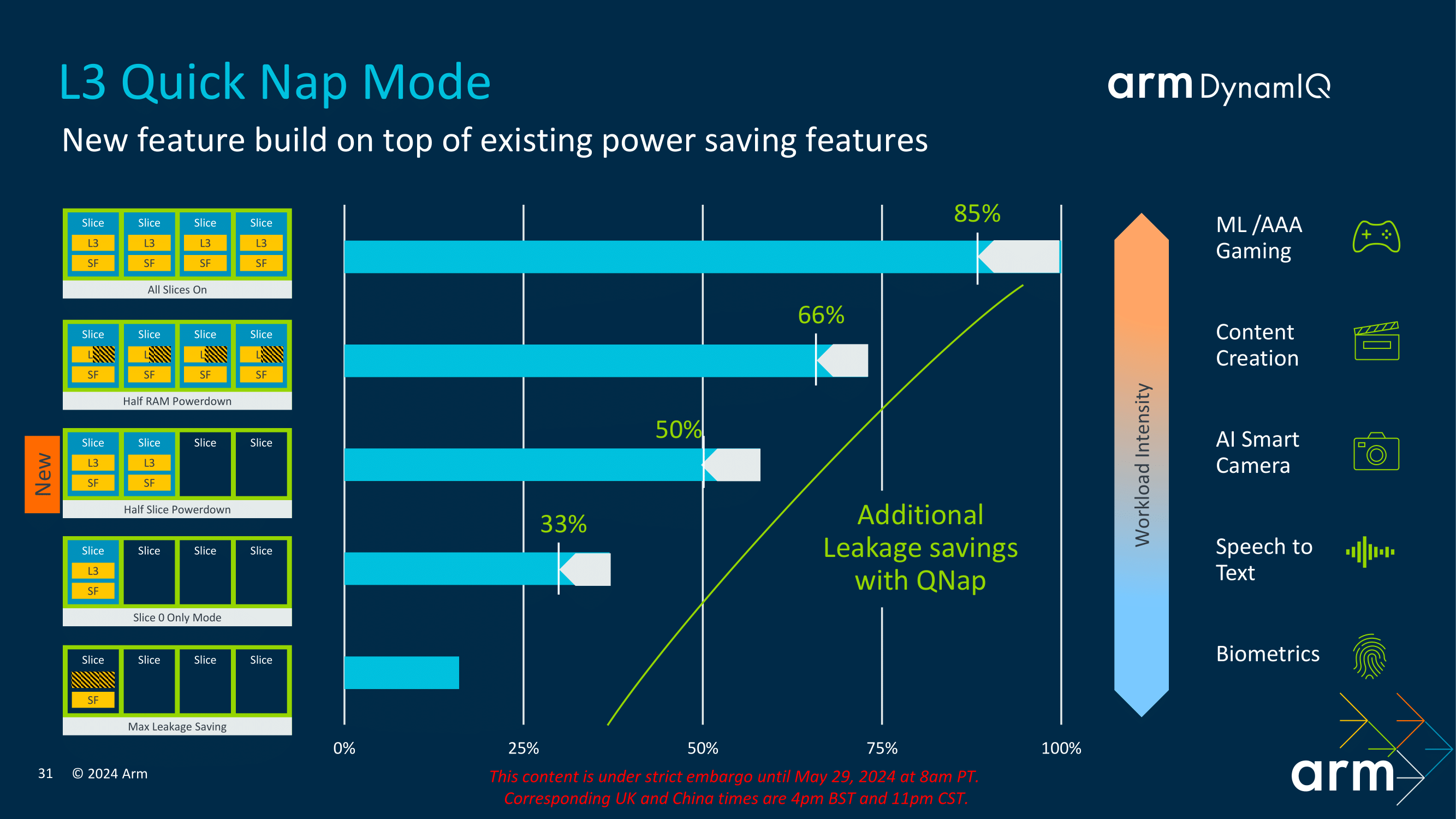
The core also features advanced power management capabilities, including dynamic voltage and frequency scaling (DVFS) and half-slice power-down modes. These features allow the Cortex-A725 to adjust its power consumption based on the current workload, ensuring energy is used efficiently without sacrificing performance.
The Arm Cortex-A520 isn’t architecturally different, nor has it been changed compared with last year’s TCS2023 introduction. Instead, it has been optimized for the latest 3 nm process technology, enhancing its efficiency and performance. This core, part of the second-generation Armv9.2 architecture, delivers some additional compute power for everyday tasks in mobile and embedded devices while maintaining peak levels of energy efficiency and reducing power consumption expected from Arm’s smallest core.
These architectural tweaks ensure that the Cortex-A520 can maximize the potential of the 3 nm process, achieving higher transistor density and better overall performance without any significant changes to its fundamental design.
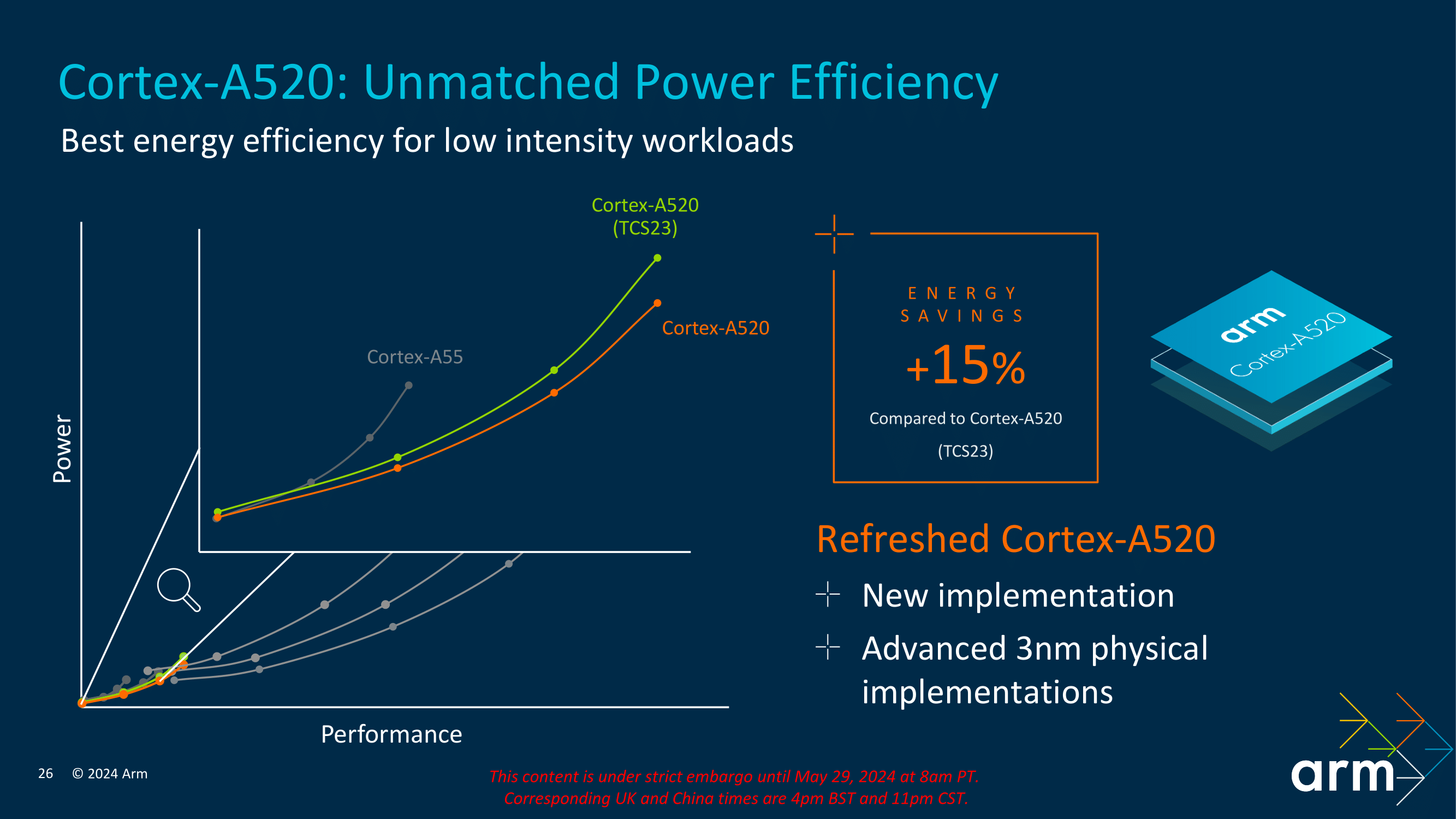
The Cortex-A520 showcases a significant 15% energy saving compared to the Cortex-A520 (TCS23). This improvement is critical for devices with prolonged battery life, such as smartphones and Internet of Things (IoT) devices. By optimizing power consumption, the Cortex-A520 ensures efficient performance without compromising energy usage.
The graph on the above slide clearly illustrates the relationship between power and performance for the Cortex-A520 compared to its predecessor, the Cortex-A55, and the previous Cortex-A520 (TCS23). The latest Cortex-A520 explicitly designed for the 3 nm notably improves power efficiency across various performance levels. This means that the Cortex-A520 consumes significantly less power for a given performance point, demonstrating Arm’s commitment to providing performance gains across 2024’s Core Cluster and focusing on refining things from a power standpoint to the smallest of the three Cortex cores.
Having attended Arm’s Client Technology Day, my initial impressions were that Arm has opted to refine and hone its IP for 2024 instead of completely redefining and making groundbreaking changes. Following on from last year’s introduction of the Armv9.2 family of cores, Arm has made some notable changes within the architecture of the latest Cortex series for 2024, with a clear and intended switch to the more advanced 3 nm process node, both with Samsung and TSMC 3 nm as the basis of client-based CSS for the 2024 platform.
The Cortex-X925, Cortex-A725, and Cortex-A520 cores have been optimized for the 3 nm process, delivering significantly touted performance and power efficiency improvements. The Cortex-X925, with its enhanced 10-wide decode and dispatch width and higher clock speeds reaching up to 3.8 GHz, looks to set a new standard for single-threaded IPC performance. Arm’s updated v9.2 platform looks ideal for high-performance applications, including AI workloads and high-end gaming, both in the mobile space and with Microsoft’s Windows on Arm ecosystem.
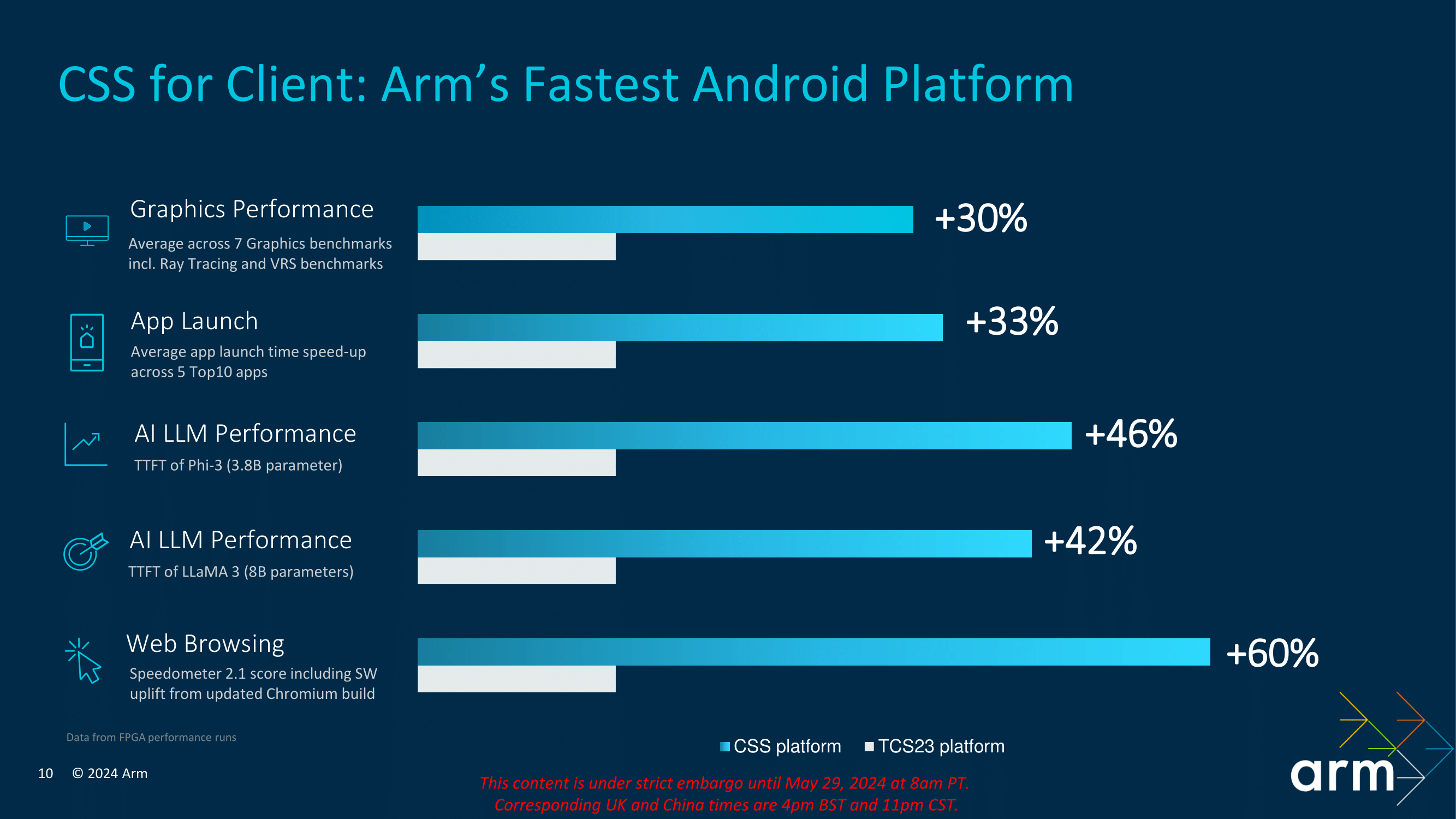
In the grand scheme of things, and from Arm’s in-house performance comparisons between the new CSS platform and last year’s TCS2023 version, Arm claims gains of between 30 and 60% in performance, depending on the task and workload. If it is to be believed and taken as gospel, the performance improvements are incredible, with the likely transition to 3 nm being the primary improver of performance rather than the underlying architectural improvements.
The Cortex-A725 balances performance and efficiency, making it suitable for several mid-range devices. Thanks to architectural enhancements such as increased cache sizes and expanded reorder buffers, Arm claims the improvements achieve up to 35% performance efficiency over the previous generation. The refreshed Cortex-A520 focuses primarily on being optimized on the 3 nm node while looking to remain unmatched in power efficiency, achieving a 15% energy saving compared to its predecessor. This core is optimized for low-intensity workloads, making it ideal for power-sensitive applications like IoT devices and lower-cost smartphones.
AI capabilities have been a significant focus in Arm’s latest offerings. The Cortex-X925 and Cortex-A725 cores primarily integrate dedicated AI accelerators, allowing access to optimized software libraries, such as KleidiAI and KleidiCV, ensuring efficient AI processing. These enhancements are crucial for applications ranging from neural language models and LLMs.

Arm also continues to support its latest Core Cluster with a usually adept and comprehensive ecosystem driven by the new CSS platform, coupled with the Arm Performance Studio and in tandem with the Kleidi AI and CV libraries. These provided tools give developers a robust foundation to fully leverage the new architecture’s capabilities. This effectively reduces the overall time-to-market and fosters innovations across various industries, such as content creation and on-device AI inferencing. The CSS platform’s integration with operating systems such as Android, Linux, and Windows (Windows on Arm) ensures a larger reach in adoption. It pushes a wider level of development, making software and applications available on more devices than in previous generations.
In summary, Arm’s move to all its latest CPU designs onto the 3 nm process technology and the refinements in the Cortex-X925 and Cortex-A725 cores demonstrate a strategic focus on optimizing existing architectures rather than making radical changes. These refinements include increased cache sizes per core, moving to a wider pipeline, and bolstering the DSU-120 Core Cluster for 2024, which certainly delivers substantial performance and power efficiency gains on paper.
While enabling new devices capable of handling demanding applications, most of these improvements in efficiency and performance are prevalent from the switch to the more advanced yet more challenging jump to the 3 nm node. As Arm continues to push the boundaries of what’s possible with its IP, these technologies should pave the way for more powerful, efficient, and intelligent devices, shaping the future of what’s possible and capable from a mobile device, whether that be in terms of the new generation of AI capable devices, or mobile gaming, Arm is looking to offer it all.