In today’s app landscape, most ideas involve some kind of social media element, which means user-generated content (UGC) is often a key feature. For developers, this presents both an exciting opportunity and a tricky challenge: how to analyze content to boost user experience and engagement.
Content analysis isn’t just about improving UX; it’s also essential for meeting the moderation requirements of app stores. When you’re developing a new app, your main focus is probably getting it off the ground quickly without burning through your budget. With so many tasks on your plate, spending too much time on content moderation might seem like a headache. But it’s a necessary one — especially if you want to avoid issues with app store compliance. Without proper moderation, your app could face penalties or even get removed from these platforms. While hiring human moderators is one option, the workload increases as your app and UGC grow. To keep things manageable, you’ll need tools that let human moderators focus only on the content that really needs their attention, while automated systems handle the bulk of the work.
As your app scales, personalized content recommendations become more important. By tracking how users interact with content, you can suggest posts that are more relevant to them. Computer vision can help by automatically categorizing images and videos, allowing you to offer smarter recommendations without manual effort.
In this post, we’ll look at how to efficiently analyze images and videos in a scalable way. We’ll cover how to build a system that automatically detects and categorizes objects in media as soon as users upload it, storing the results in a database for future use. With this setup, you’ll be better equipped to handle UGC, keeping your app both compliant with store policies and engaging for your users.
Here are the key things to consider when building a cloud-based solution for these challenges:
- Simple setup and deployment: Easy integration with your media storage, databases, and front-end.
- Scalability: Ability to process anywhere from a handful to thousands of images and videos daily.
- Cost efficiency: No upfront costs, and you only pay when the system is active.
By focusing on these essentials, you’ll be able to manage UGC at scale while keeping your app compliant and offering a better experience for users.
SOLUTION BASED ON AWS REKOGNITION
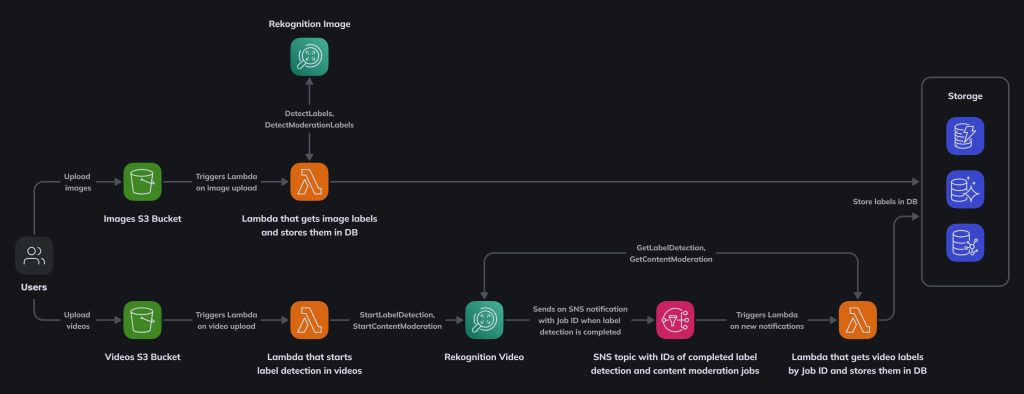
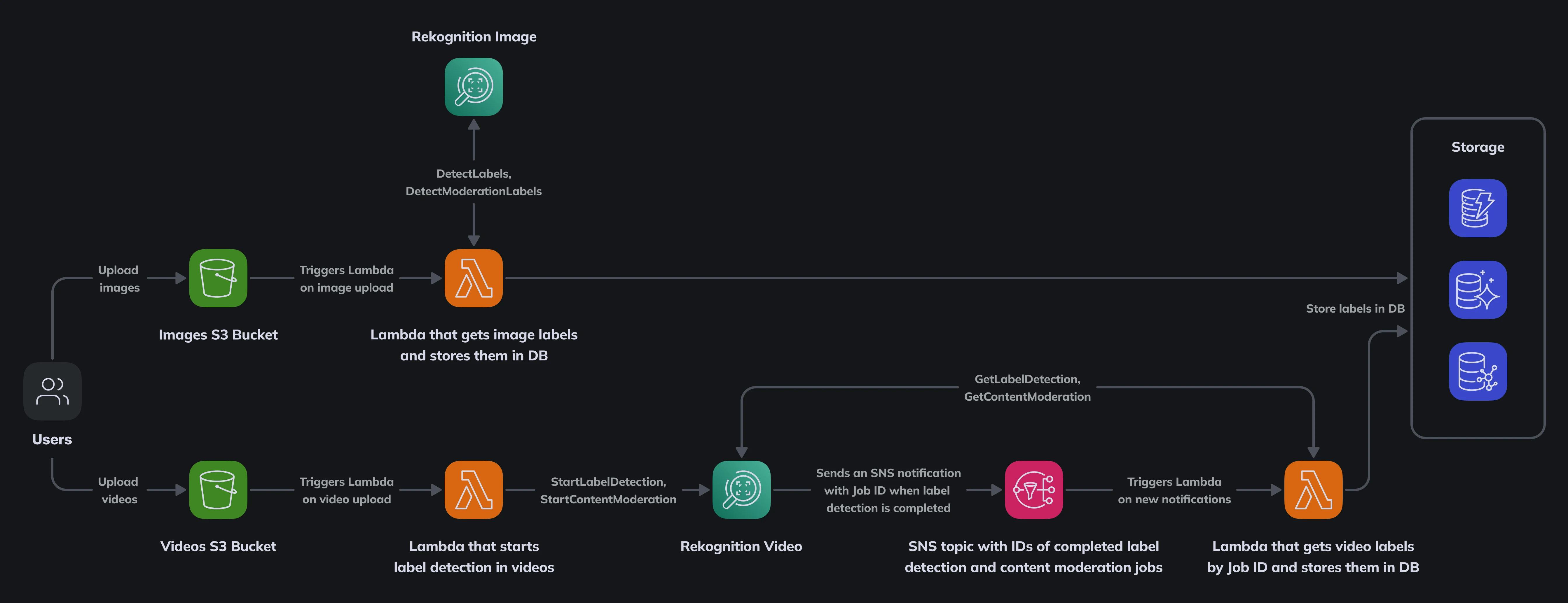
Based on these requirements we suggest a serverless solution that utilizes a few AWS services:
- S3 buckets for user uploads: one for images and one for videos
- Rekognition for detecting objects in images and videos and getting labels and moderation labels for those objects
- Lambda functions to start object detection in new images and videos and then store detected labels in the DB
- SNS topic for notifications for the processed videos
There are 2 workflows in this solution: one for images and one for videos. We won’t focus on storage (DB type, schema, access patterns, etc) and IAM roles / policies / permissions at this time.
DETECTING OBJECTS IN IMAGES
Let’s start with images. When a user uploads an image to the images S3 bucket, we trigger a Lambda function that sends 2 requests to the Rekognition API: DetectLabels and DetectModerationLabels. In a few seconds we get responses with labels and moderation labels and print them. Then we can process the labels however we want and then put them in a database. Here’s the code for that lambda:
import boto3
s3_client = boto3.client('s3')
rekognition_client = boto3.client('rekognition')
def lambda_handler(event, context):
# get S3 bucket name and object key from the event
bucket_name = event['Records'][0]['s3']['bucket']['name']
object_key = event['Records'][0]['s3']['object']['key']
# call Rekognition to detect labels
detect_labels_response = rekognition_client.detect_labels(
Image={'S3Object': {'Bucket': bucket_name, 'Name': object_key}},
)
labels = detect_labels_response['Labels']
# call Rekognition to detect moderation labels
detect_moderation_labels_response = rekognition_client.detect_moderation_labels(
Image={'S3Object': {'Bucket': bucket_name, 'Name': object_key}},
)
moderation_labels = detect_moderation_labels_response['ModerationLabels']
# we can now store the labels in a database, or take some other action
print('Labels:', labels)
print('Moderation labels:', moderation_labels)
return {
'statusCode': 200,
'body': 'OK',
}
DETECTING OBJECTS IN VIDEOS
For videos, the solution is a bit more complicated. Unlike images, videos take more time to be processed: detecting labels even in a short video can take minutes, so we don’t want to keep the Lambda function running while the video is being processed. Because of that, Rekognition Video API has StartLabelDetection and StartModerationLabelDetection instead of DetectLabels and DetectModerationLabels as in Rekognition Image. Rekognition Video can be used with an SNS topic for notifications about processed videos, so the Lambda that is triggered on video uploads will just request video processing, provide the ARN of the SNS topic that we’ll monitor for notifications, and then exit:
import boto3
import re
# Lambda execution role must have access to S3, Rekognition
# and IAM PassRole (on resource sns_topic_publisher_role_arn)
s3_client = boto3.client('s3')
rekognition_client = boto3.client('rekognition')
# SNS topic (and publisher IAM role) for notifications on completed Rekognition jobs
sns_topic_arn = 'arn:aws:sns:us-east-1:123456789012:RekognitionVideoNotificationsTopic'
sns_topic_publisher_role_arn = 'arn:aws:iam::123456789012:role/RekognitionVideoNotificationsTopicPublisherRole'
# regex used to normalize the object key for the client request token
client_request_token_symbols_to_skip = r'[^a-zA-Z0-9-_]'
def lambda_handler(event, context):
# get S3 bucket name and object key from the event
bucket_name = event['Records'][0]['s3']['bucket']['name']
object_key = event['Records'][0]['s3']['object']['key']
# normalize the object key for the client request token
client_request_token_obj_key = re.sub(client_request_token_symbols_to_skip, '_', object_key)
# call Rekognition to start a label detection job
start_label_detection_response = rekognition_client.start_label_detection(
Video={'S3Object': {'Bucket': bucket_name, 'Name': object_key}},
NotificationChannel={
'RoleArn': sns_topic_publisher_role_arn,
'SNSTopicArn': sns_topic_arn,
},
ClientRequestToken='label_detection_' + client_request_token_obj_key, # unique request token to avoid duplicate jobs
)
label_detection_job_id = start_label_detection_response['JobId']
print(f'Started label detection job with ID {label_detection_job_id}')
# call Rekognition to start a moderation label detection job
start_content_moderation_response = rekognition_client.start_content_moderation(
Video={'S3Object': {'Bucket': bucket_name, 'Name': object_key}},
NotificationChannel={
'RoleArn': sns_topic_publisher_role_arn,
'SNSTopicArn': sns_topic_arn,
},
ClientRequestToken='content_moderation_' + client_request_token_obj_key, # unique request token to avoid duplicate jobs
)
content_moderation_job_id = start_content_moderation_response['JobId']
print(f'Started content moderation job with ID {content_moderation_job_id}')
return {
'statusCode': 200,
'body': 'OK',
}
When the video is processed, Rekognition sends a message to the SNS topic we provided. The message looks like this for regular labels (API = StartLabelDetection):
{
"JobId": "unique-job-id",
"Status": "SUCCEEDED",
"API": "StartLabelDetection",
"Timestamp": 1706141533445,
"Video": {
"S3ObjectName": "upload-12345.mp4",
"S3Bucket": "video-uploads-1234567890"
}
}
And for moderation labels it looks like this (API = StartContentModeration):
{
"JobId": "unique-job-id",
"Status": "SUCCEEDED",
"API": "StartContentModeration",
"Timestamp": 1706141533445,
"Video": {
"S3ObjectName": "upload-12345.mp4",
"S3Bucket": "video-uploads-1234567890"
}
}
To receive that message, we use another Lambda that is triggered on new publications in the SNS topic we provided when we called StartLabelDetection and StartContentModeration in the previous Lambda. After reading the JobId from the message we can use it with GetLabelDetection and GetContentModeration API to retrieve the actual labels and moderation labels from Rekognition:
import boto3
# requires access to Rekognition GetLabelDetection and GetContentModeration APIs
rekognition_client = boto3.client('rekognition')
def lambda_handler(event, context):
# get SNS message from the event
msg = event['Records'][0]['Sns']['Message']
# get job id and API name from the message
job_id = msg['JobId']
rekognition_api = msg['API']
# call the appropriate Rekognition API to get the labels
if rekognition_api == 'StartLabelDetection':
response = rekognition_client.get_label_detection(JobId=job_id)
labels = response['Labels']
print('Labels:', labels) # we can store the labels in a database
elif rekognition_api == 'StartContentModeration':
response = rekognition_client.get_content_moderation(JobId=job_id)
moderation_labels = response['ModerationLabels']
print('Moderation Labels:', moderation_labels) # we can store the labels in a database
return {
'statusCode': 200,
'body': 'OK',
}
The labels are returned with categories, confidence scores, bounding boxes, and also timestamps if the input is a video. That information can be used to categorize the content for recommender systems, and for automated content moderation: if some type of content that is not allowed in the app is detected, it can be automatically hidden or a human moderator can be notified.
In summary, this automated object detection solution aligns well with the key priorities of app developers that deal with user-generated images and videos. It offers a rapid deployment process, minimal code maintenance, and no idle-time costs, making it both efficient and cost-effective. Its flexible design allows for easy extension and customization, providing a scalable tool that can significantly reduce the time spent on content moderation. By integrating this solution, developers can also enhance the performance of recommender systems, delivering a better user experience with less effort.