AI
Anatomy of a Parquet File | Towards Data Science
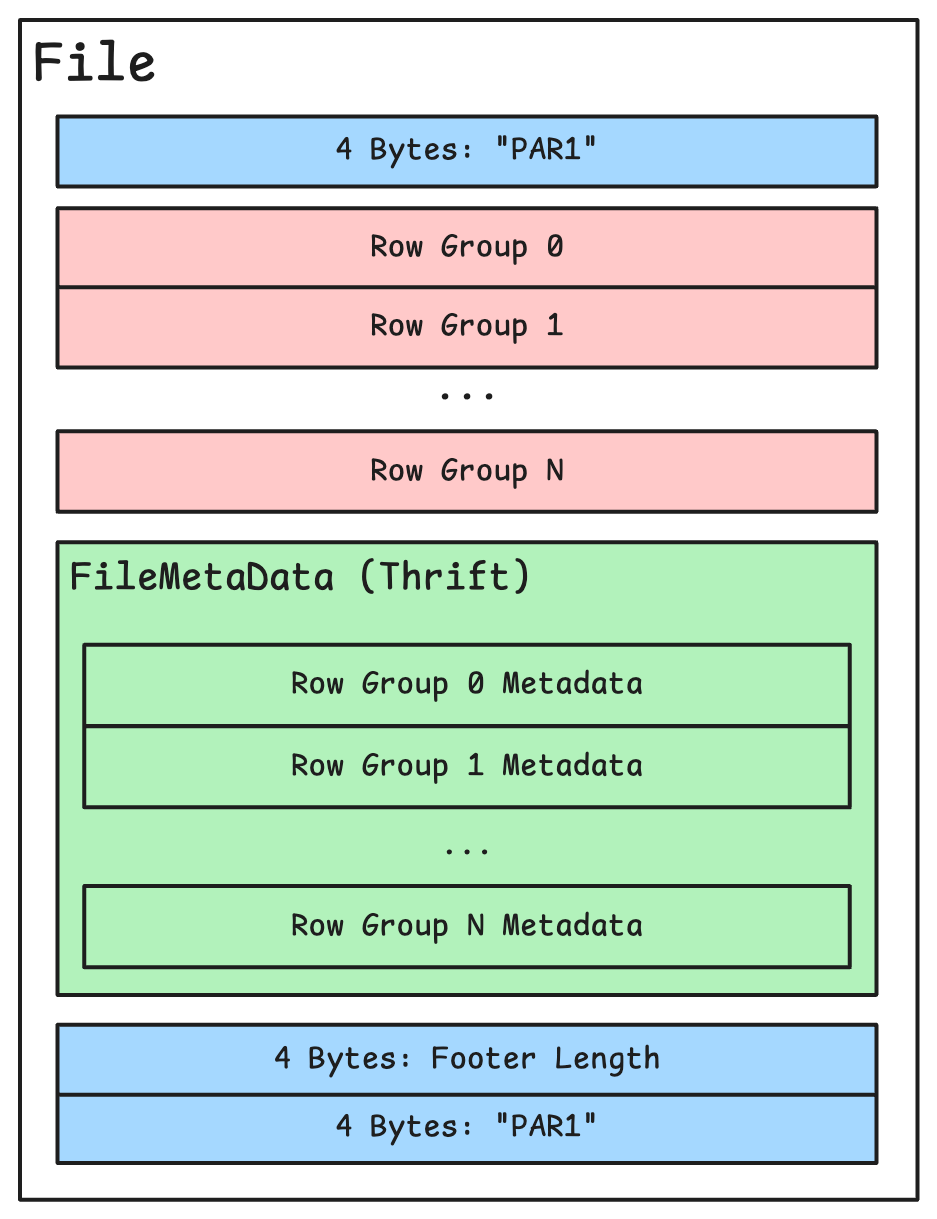
In recent years, Parquet has become a standard format for data storage in Big Data ecosystems. Its column-oriented format offers several advantages: Faster query execution when only a subset of columns is being processed Quick calculation of statistics across all data Reduced storage volume thanks to efficient compression When combined with storage frameworks like Delta Lake or Apache Iceberg, it seamlessly integrates with query engines (e.g., Trino) and data warehouse compute clusters (e.g., Snowflake, BigQuery).